01.11.2020 site-news webdesign techarticle
Optimizing my website
I have spent the last week optimizing everything. Like, really, everything.
It was a painful road, with the revelation, that foundation.css is abandoned and causes too many issues. The
biggest was definately the content layout shifting. I rewrote large portions of the my file, tried everything, but smacking
one mole, another one turned up. So I just switched frameworks and I am now using Bulma
, properly,
using SCSS. I want to write down here, what I did to make my website as fast as possible. If you are an old webdev
geezer or gal, then this is probably all old news to you.
Identifying and naming the metrics
Google has guidelines which metrics of a website’s performance are the most important. These are called web vitals . They consist of the following:
| METRIC | DESCRIPTION |
|---|---|
| Content Layout Shift | Wether items move during loading. This is a real bad one. |
| First Contentful Paint | The time from clicking to seeing something |
| Largest Contentful Paint | The element that takes the longest to draw |
| Speed Index | The rendering speed of your websitem, blocking resources make this slow. |
| Time to interactive | From the time of the click until the site is usable |
| Total Blocking Time | How long it takes until your site is interactive. |
You can test for those with either “Lighthouse” in Google Chrome’s Developer Tools or online with
Google PageSpeed Insights
.
We will talk about these values more over the course of this series.
The server is the first piece of work
My webhoster
uses openresty as proxy to serve my web page, running Apache on the
backend. So, the .htaccess is the first beast to tackle. When a webserver sends a document, it also sends a timestamp at
which the document expires and the browser shall redownload it. This applies to all documents, including fonts, images, css
and javascript. So we want all our datafiles to be cached by the browser as long as it is feasible,as long as they don’t
change. This is not part of the web vitals, but it is measured and also important. Data costs money and high bandwidth
is not always available.
A browser determines also via the so called E-Tag
that is sent with the document, if a resource has changed.
That is basically just a hash of the file. The first time a server receives this file,
it will store the E-Tag and send it to the server again, when the user reloads and the document’s cache is expired. If
the E-Tag sent matches the E-Tag on the server, the server will not send the new document along with HTTP status code 200,
but it will send a 304 not modified. This way the browser knows that the document is still up-to-date.
How comes cache-control into play here?
As long as the local cache isn’t expired, the browser will not try to fetch the resource. If the local cache is out date, it will try to fetch the expired document again and send the E-Tag. If the document has not changed, the server will not send it as explained above.
You can see cache-control in effect if you change the CSS and no changes happen on reload. This is why modern sites use fingerprinting. Take a peek at this site’s html code to see how that works. The css file has a fingerprint aka hash in the file name. If the document changes, the static site generator I use, will change the fingerprint. Since the browser does not have this file locally, it is forced to fetch it. Be careful with this, it circumvents caching. Don’t stick all your JS dependencies into the same file with your own code when fingerprinting, so those do not have to be redownloaded.
Sending caching policies and reducing data size
To make the browser cache the files, we can instruct Apache to send these headers with this entry into the .htaccess or
vhost configuration, depending on if you are having a managed setup or your own root server. In case of the former,
your hoster must also allow the use of a .htaccess. This is not always the case.
| |
If this seems pretty straight forward to you, then because it is. The syntax is dead easy and makes sense while reading it. Gotta love this. I have set html and text to 1 hour, as it may change and instruct the browser to check for an update. Anything else probably never changes. Fonts for example or pictures. This is a generic statement and may not always apply, but these are indeed sane values.
Now, the real interesting part comes with this piece, which we also need to add:
# Append "public" to header "Cache-Control"
<IfModule mod_headers.c>
Header append Cache-Control "public"
</IfModule>
There are 4 types of caching: public, private, no-cache and no-store. Now what the hell does this mean?
You may be a bit surprised that your computer is not the only one caching web pages. Many networks along the way and most
prominently your personal ISP will do this, to speed up requests and save bandwidth. As bandwidth needs exponentially
grows, every gigabit outgoing is saved money (because you only pay for outgoing transit, not incoming and nothing for
interconnectes, except your hardware). So, setting this to public means that every squid cache
out there where the connection passes along will cache your pages. Neat, isn’t it?private means that only the browser may cache it, while no-cache means that it is not supposed to be cached at all.
Last but not least, no-store means that archives cannot store the page.
All this stuff can be seen in your browser’s dev tools on the network tab.
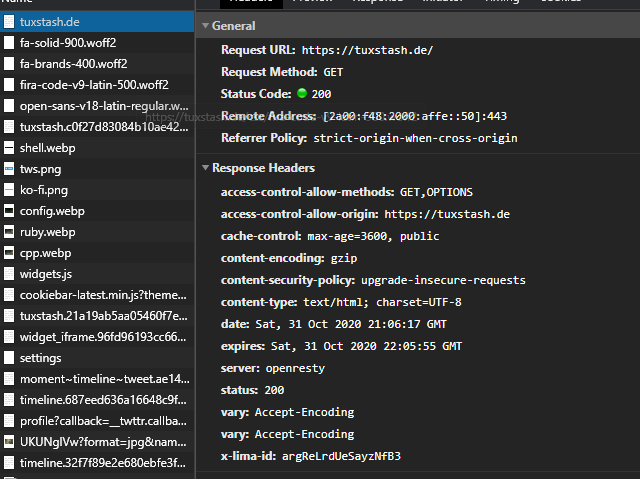
Be aware that embedded resources do not follow these rules, since they are not served from your server. For example, the embedded twitter widget on the bottom totally “destroys” my rating towards my caching policy:
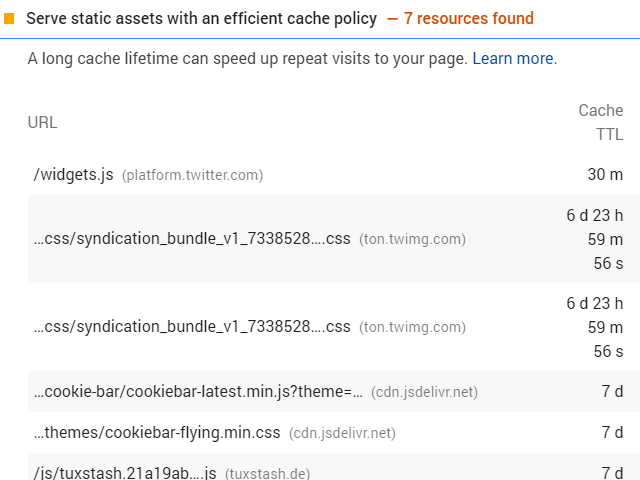
You can also see on those images that the content is gzipped. This reduces the effective data the is sent. Your server must support this, but in the end, it is just one entry in the server configuration. Most hosters do this by default, as it saves data and therefore money, so check the network tab before you deploy a config like this:
| |
Changing the protocol
By default, Apache 2 runs on HTTP/1.1. This was the first draft and is designed to transmit text. That is fine, since HTML is text. CSS as well. Images are not, but the server can change the transmission mode for that on the fly. But there is one major flaw in this approach. The browser has to request each single file and they are transmitted line by line and the format is not known in advance. This is inherently flawed in todays environment.
So some very smart people over at Google whipped up HTTP/2. The main advantages are:
HTTP/2 is fully binary. It structures data in so called frames, that are read before the actual payload and fixed in size. The browser knows the length of those frames (somewwhat similar to Ethernet Frames ). Knowing the length means you do not have to wait for a magic token in the stream, you can read the amount of bytes needed directly that are required to know the properties of the payload. Here is some pseudo code to visualize this:
// HTTP/1.x http.foreach (received character){ read(); process(); } // HTTP/2 data1 = stream.read_bytes(20); data2 = stream.read_bytes(40);Hope this makes some sense. Bottom line is, reading it this way is more efficient, parsed with fewer CPU cycles.
Multiplexing. In HTTP/1.x, you want to make multiple requests at the same time to get all the images, css and what not. However, each connection is in TCP, requiring the network to make a handshake for each of them. TCP handshakes first send a packet called SYN, SYN/ACK, then an ACK. So this are 3 roundtrips to establish an connection. This takes time. HTTP/2 eliminates this by being able to send all frames simultaniously via the same connection. So you should now see how this benefits us. It also eliminates the latency of having to do all these additional handshakes.
One connection per origin. With above being said, one should know that each remote origin needs one connection. This means that it is important to not introduce too many different domains from which to get data. If you can, download the css or js from github and serve it yourself, or stick with the same cdn, such as google or jsdeliver etc.
HTTP/2 can push. Instead of waiting for the browser to request a file, the protocol will actively send the data needed by the website. However, the browser can refuse that, if needed, by sending a frame containing a reset signal.
So, how do I get HTTP/2? With Apache2, it is really simple. First, we need to load an extension:
$ a2enmod http2
This will enable HTTP/2 on your Apache. Make sure to not use prefork, when you do this, as this introduces some
unwanted side effects, negating the effects
,
but since the default is mpm, this shouldn’t be an issue.
Next, add this line to your apache.conf or any vhost excplitly:
Protocols h2 h2c http/1.1
Then reload apache and watch the network in Firefox/Chrome Dev Tools. Enable the column protocol to see your files
flowing in via HTTP/2.
With all these in place, our backend is finally ready for the big show. There are surely more things you can do to optimize server-side, but these are the big ones (besides having enough CPU and RAM etc).
This concludes the first part of this series. In the next part, we are going to talk about some metrics that PageSpeed Insight suggest.
![]()
![]()